本文来自网易杭州研究院数据挖掘团队,作者根据项目实战经验,分享了深度学习的应用,包括一个用于图像理解的弱监督学习算法,和一个基于多维度建模的推荐算法。基于业界对深度学习存在误解的现象,作者在进入项目之前也对深度学习的概念、主流算法和关键步骤进行了科普,当然,也包含从业务角度的理解。
近几年,深度学习在图像、音频处理等领域得到了广泛的应用并取得了骄人的成绩,本文根据笔者的工作实践,谈谈对深度学习理解,以及我们的应用和经验。文章涉及的很多结论,是笔者个人的理解和不充分实验的结果,所以难免谬误,请读者不吝指正。
机器学习就是学习对象的表示
“机器学习/深度学习模型依靠左右互搏,可以迅速达到很高的智能水准。”、“人工智能/深度学习能毁灭人类的奇点即将来到!” 网络上经常出现这类观点,让笔者非常惊讶,而让笔者更惊讶的是,很多人居然相信了。那么,什么是机器学习呢?
机器学习的对象是我们生活中所接触到的一切事物,这些事物包含自然界的事物,以及人类抽象出来的概念。笔者认为,机器对于这些对象的学习,本质上是使用机器语言对其特征进行表示。例如,对性别的识别,其实就是计算机将样本表达成男/女两种形式。
目前的计算机是以CMOS管为基础的冯诺依曼结构,其运算是线性的,数据的表达是0维度的。如何让低维度的计算机处理高维度的对象?这个表示的过程其实就是机器学习的过程。就如同处在二维空间的蚂蚁无法感知三维世界一样(图1),笔者认为目前的计算机0维的运算结构无法真正实现类似人类智能的人工智能,因为这种表示是不充分的。

比如,自然界中的事物的有其独特的属性,同时是相互关联的,这些规律有的被人类发现,有的则依旧未知,同时数字的表达能力是有限的,如图2所示,这个是从英国地图的轮廓,如果使用数字只能够去逼近,永远无法进行准确描述。
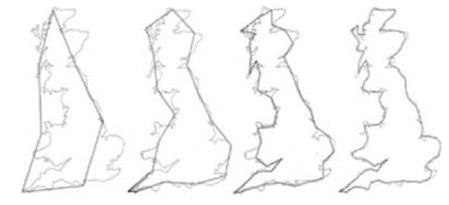
我们使用计算机对每个事物进行二进制编码可以区别每个事物,但却忽略了事物的属性以及相互之间的关联性。机器学习则是在人为设定的规律前提下,寻找对事物的表示,并在一定程度上保留这种关联性。
从宏观上看,笔者认为目前多数的人工智能可以视为一个表示和索引的过程:机器学习完成了表示,人工智能部分就是基于表示的索引。根据目标,我们可以用多种方法,将对象表达成多种数学结构、数字、向量、矩阵等等。下面就是对这些表达式进行存储,这些表达式具有明确的意义,比如男女分类中表达式就是用(0,1)和(1,0)分别表示男女两种模式。针对一幅照片进行预测时,我们首先需要寻找其表达式(0.3,0.7),在存储的模式中索引其表达的意义。
深度学习简述
简单地说,深度学习就是使用多层神经网络对对象进行表达。当然这里面衍生出了很多的具体技术和方法。下面简要介绍深度学习里面常用的概念和典型的网络,这些会在后续的项目实践中涉及。
卷积神经网络(Convolutional Neural Networks, CNN)
CNN是对传统的神经网络的简化。举个例子,1,000×1,000的图像,如果隐含层数目与输入层一样,即也是1,000,000时,那么输入层到隐含层的参数数据为1,000,000×1,000,000=10^12,当隐层不止一层,参数将是一个巨大的量级,现实中我们的硬件资源是有限的,所以引入了卷积神经网络。
卷积神经网络使用卷积核实现了两个目的:1,减少参数;2,对空间进行编码。
如何减少参数?
采用局部连接取代全连接,即全局相关变成局部相关。基于这样一个现实,图片中像素点之间是存在空间相关性的,强度跟间距成负相关。所以笔者认为局部化实质上是相关性较弱的远处像素点,所以存在性能的损失。
共享参数,基于这样的假设,相同距离的像素点之间的相关性相同,当然这也是一种无可奈何的折中。
循环神经网络(Recurrent Neural Networks, RNN)
RNNs的目的使用来处理序列数据,RNNs会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。
RNNs已经被实践证明对NLP是非常成功的,如词向量表达、语句合法性检查、词性标注等。在RNNs中,目前使用最广泛、最成功的模型便是LSTMs(Long Short-Term Memory,长短时记忆)模型。
神经网络的反馈算法
神经网络依靠反馈算法进行参数调整,实现将对象转化成所预期的数学表示。 ΔC 表示loss函数,
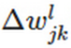
表示网络的权重,那么更新方程为:
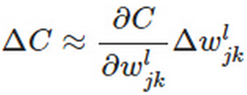
上面是一个标准的偏微分的公式,一层一层地推导,又可以表示为:
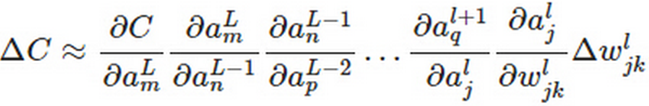
上面是一个标准的链式偏微分公式。
损失函数
说到了损失函数(loss)函数,简单的讲就是对上面所说的规律的表达。下面简述下几个用过的损失函数和其特性。
方差损失函数
比如对于一个神经元(单输入单输出,sigmoid激活函数),定义其损失函数为:
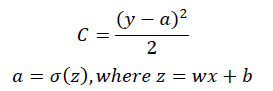
其中 γ 是我们期望的输出, α 为神经元的实际输出。
在训练神经网络过程中,我们通过梯度下降算法来更新 ω 和 b,因此需要计算损失函数对 ω 和 b 的导数:
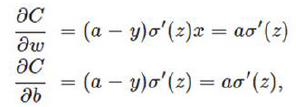
如何更新 ω 和 b ,才能使 C 减小?
即ΔC < 0, 由于
,所以使
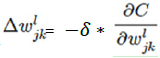
时,可以保证 C 始终减小(平方始终大于等于0),所以 ω 和 b 的更新公式为:
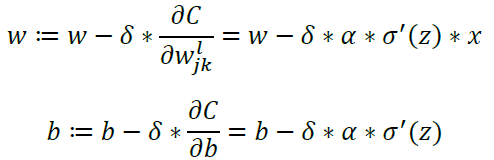
因为Sigmoid函数的性质,导致 σ'(z) 在 z 取大部分值时会很小(如图3标出来的两端,几近于平坦),这样会使得 ω 和 b 更新非常慢(因为 δ*α*σ'(z) 这一项接近于0)。
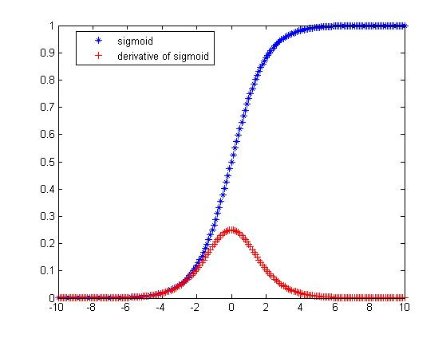
交叉熵损失函数(cross-entropy cost function)
为了克服这个缺点,引入了交叉熵损失函数(下面的公式对应一个神经元,多输入单输出):

其中 y 为期望的输出, α 为神经元实际输出。
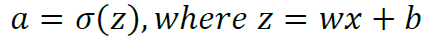
当真实输出 α 与期望输出 y 接近的时候,损失函数接近于0。另外,它可以克服方差损失函数更新权重过慢的问题。我们同样看看它的导数:
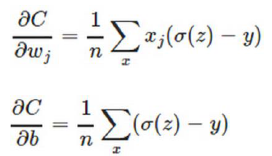
可以看到,导数中没有 σ'(z) 这一项,权重的更新是受 σ(z)-y 这一项影响,即受误差的影响。所以当误差大的时候,权重更新就快,当误差小的时候,权重的更新就慢。这是一个很好的性质。
对数似然函数(log-likelihood cost)
深度学习中进行分类普遍的做法是将softmax作为最后一层,此时常用的是损失函数是log-likelihood cost。
Logistic回归用的就是Sigmoid函数,softmax回归是Logistic回归的多类别推广。log-likelihood损失函数在二类别时就可以化简为交叉熵损失函数的形式,其中 y 可以取 k 个不同的值。因此,对于训练

,我们有
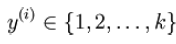
。
损失函数为:
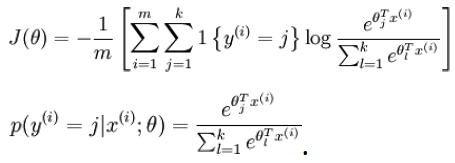
其中
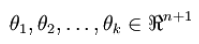
是模型的参数。
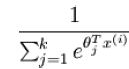
这一项对概率分布进行归一化。
经过求导,我们得到梯度公式如下:
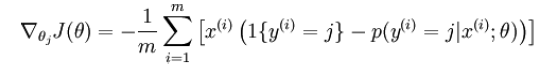
调参技巧
网络设计好后,训练网络,进行调参是重头戏了。调参可以调节的参数很多,这里主要讲讲学习速率(η)和正则项系数(λ)和Batch Size。
学习速率
学习速率太小,则会使收敛过慢,如果学习速率太大,则会导致损失函数振荡。在训练过程中,可变学习率可以取得更好的效果。
正则项系数
在确定好learning rate后,给λ一个值(比如1.0),然后根据validation accuracy,将λ增大或者减小10倍(增减10倍是粗调节,当你确定了λ的合适的数量级后,比如λ = 0.01,再进一步地细调节,比如调节为0.02,0.03,0.009之类。)
Batch size
batch数太小,而类别又比较多的时候,真的可能会导致loss函数震荡而不收敛,尤其是在网络比较复杂的时候。Batch size太大,可以较快的收敛,但学习到的网络精度会比较低。一般根据GPU的内存,选择8的倍数,然后是稍微大一点。
深度学习在图像弱监督学习中的应用
这里采用项目的方式谈谈笔者在使用CNN网络对图像进行处理的一些工作和总结。
监督学习的方式存在以下的一些先天缺陷:
机器学习的结果的优劣很大程度上取决于数据的数量和质量。这意味数据的准备需要进行大量的人工标注工作。标注的质量,即使在预先设定的有限类别内,准确性也是因人而异的。
把图像理解转换为解决特定的有限类别的分类,使得训练出来的模型仅仅适用于有限类别的分类。比如,人脸识别的模型就难以去识别大猩猩的脸,即使他们很像,在不同的应用场景必须训练不同的网络。
互联网上存在大量的图片和文本,观察发现,这些图片和围绕其的文本都是存在相关性的。基于这种相关性,其实也可以实现无监督或弱监督学习。这里要介绍的,就是一个笔者提出并实现的弱监督图像理解算法–Image2Words。
算法简述
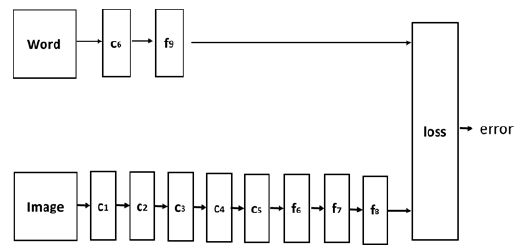
使用CNN网络对图像进行特征提取,同时使用CNN网络对文字进行表示,最小化对应文字和图像的误差。所以,模型分为两个部分,分别是对应文字和图像。
图片对应的网络包含5个group的卷积、2层全连接图像特征、一层全连接分类特征记为image_fc。文字包含的网络采用一个卷积,1层全连接分类特征记为word_fc。保证图片和其对应的文字的全连接的分类特征输出最相似。
模型的应用
Image2Words作为图片特征抽取模块,实现基于图片进行商品检索和分类功能。深度特征与传统的图像特征对图像的描述侧重点不同,前者尤其高层网络的特征更加着重在类别描述,而SIFT特征则是对局部特定的形状进行描述。
图5是《Visualizing and Understanding Convolutional Networks》里面的一张每层输出的可视化结果。

从图5可以看到,底层的特征是非常局部的颗粒化特征;层数越高,特征表现越全局化。在图像特征抽取时,可以适当的使用低层特征以增加图片细节信息。
- 相似商品检索
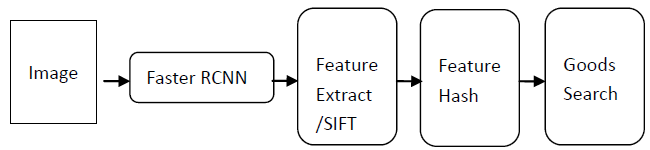
整体的流程如图6,先使用Faster-RCNN进行箱包检测并截取,采用Image2Words提取截取的箱包图片特征,对特征进行Hash操作,在商品库中对Hash后的Feature进行匹配,找到得分最高的商品信息。
- 相同商品判别
同品判断的流程跟上面差不多,只是最后训练SVM或其他分类器进行特征融合,如图7。

使用SVM对特征进行融合,并进行同品校验对于像商品,人脸校验和色情图片识别的这类正负样本不均衡的分类问题,如何去选取“边界样本”非常重要。在实现过程中,直接选择loss比较大的Pair来构建样本,效果也不错。
效果展示
图像理解
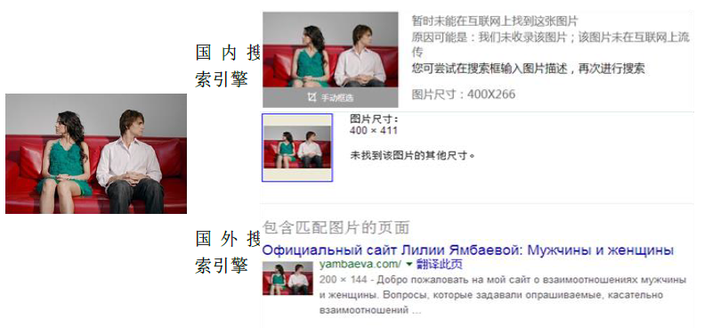
下面来看看这种弱监督学习后的网络对图像理解能力。给出的理解词汇中,笔者过滤掉了人名,并只展示部分得分较高的词汇。测试图片源自网络,并不包含在训练样本中。同时给出该图片在国内外知名搜索引擎的检索结果,作为对比。图片下方的单词是Image2words给出的结果。

牛肉, 0.126, 香花, 0.1, 馆子, 0.1, 羊肉, 0.1, 鸡翅, 0.1, 美味, 0.1, 牛仔骨, 0.1, 章鱼烧, 0.1, 苏州, 0.1, 阳春面, 0.1, 腊肠, 0.1, 汉子, 0.083, 猪油, 0.08, 奉上, 0.077, 葱油, 0.075, 冷盘, 0.075, 香嫩, 0.074, 美食, 0.072, 放入, 0.07, 西安, 0.064, 面包, 0.063, 妈妈, 0.058, 馄饨, 0.053, 都是, 0.051, 干辣椒, 0.05, 爽口, 0.05, 推荐, 0.049, 蒜头, 0.049, 麻酱, 0.048, 涮羊肉, 0.043, 肉夹馍, 0.041
图8 食物图像理解对比
合体, 0.139, 婚戒, 0.129, 催婚, 0.123, 捞金, 0.115, 放荡, 0.1, 肉麻, 0.1, 激吻, 0.096, 双喜临门, 0.09, 恩爱, 0.087, 美人归, 0.087, 撒娇, 0.085, 婚纱, 0.084, 十指紧扣, 0.083, 谎言, 0.083, 新娘, 0.078, 粉丝, 0.073, 重口味, 0.071, 猜想, 0.067, 张馨予, 0.065, 黄晓明, 0.064, 红毯, 0.061, 孤独, 0.061, SVS, 0.057, 婚姻, 0.056, Tiffany, 0.053, 致命, 0.052, 娱乐圈, 0.051, 金句, 0.051, 女女, 0.051, 女星, 0.049, 颜值, 0.049, 恋爱, 0.047, 感叹, 0.047, 对决, 0.045, 男人, 0.045, 分手, 0.043, 频出, 0.04, 宋丹丹, 0.039, 上演, 0.038, 饭们, 0.038, 甜蜜, 0.034, 明白, 0.033, 充满, 0.032, 秀恩爱, 0.032, 坛子, 0.031, 钻戒, 0.031, 老公, 0.03, 嫁出去, 0.028, 来了, 0.027, 女方, 0.026, 脑洞, 0.022, 女明星, 0.022, 男生, 0.022, 结婚, 0.019, 赵薇, 0.019, 友人, 0.018, 俏皮, 0.017, 夫妻间, 0.016, 花朵, 0.016, 戒指, 0.015, 尖叫, 0.015, 榴莲, 0.015, 广告商, 0.015, 骄傲, 0.014, 张大, 0.014, 醉了, 0.014, 网友, 0.014, 一说, 0.014, 巴掌, 0.013, 0.013, 假的, 0.012, 大玩, 0.012, 揭露, 0.012, 着急, 0.012, 隐瞒, 0.011, 你我, 0.011
图9 人像图像理解对比

货车, 0.272, 沪昆高速, 0.2, 卡车, 0.178, 起火, 0.163, 空车, 0.16, 追尾, 0.152, 司机, 0.15, 撞上, 0.14, 面包车, 0.138, 摩托, 0.137, 摩托车, 0.123, 连环, 0.122, 身亡, 0.112, 小货车, 0.1, 装载机, 0.1, 情急, 0.1, 事故现场, 0.1, 辽中县, 0.1, 被撞, 0.1, 逆行, 0.095, 发生交通事故, 0.094, 抛锚, 0.087, 猛撞, 0.083, 撞翻, 0.079, 指示, 0.075, 侧翻, 0.073, 卷入, 0.072, 公交车, 0.072, 高架, 0.071, 火车, 0.069, 小型货车, 0.067, 拐弯, 0.066, 新疆, 0.062, 行驶, 0.062, 事故, 0.062, 公路, 0.058, 专用车, 0.054, 大货车, 0.051, 交警, 0.051, 车主, 0.049, 驾驶室, 0.048, 损坏, 0.042, 车祸, 0.042, 麻江, 0.04, 牌照, 0.039, 车手, 0.039, 车子, 0.039, 失控, 0.039, 兰州, 0.038, 公交站牌, 0.037, 车头, 0.037, 驾驶员, 0.037, 碰撞, 0.035
图10 装车图像理解对比
对比上面三幅图,国外搜索引擎对三幅图的理解都失败了,国内搜索引擎给出了最后一幅图中包含轿车的结果。Image2word给出的信息量相比于目前两大搜索引擎的算法要丰富得多。
基于Image2Words模型的以图搜图
如图11所示,是基于Image2Words模型的以图搜图的结果。

深度学习在个性化推荐中的应用
推荐系统本质上是预测用户意图。意图是基于当前所有因素的规律性反应。意图具有不可预测性:影响意图的因素繁多,很多难以探知。比如饿了是肠胃的状态在脑中的反馈,不易探知。饿了跟上次吃饭的时间、饭量、吃饭的内容、期间的消耗、个人体质等等因素相关,这些因素是难以探知的。现实推荐中,我们忽略不可知和难以探知的因素,根据已掌握信息可以一定程度上实现意图预测。
推荐系统建模
推荐系统涉及的对象主要有两个,推荐对象(User)和推荐内容(Item)。根据信息的可获知性和时变性,将User和Item划分成三部分构成,静态信息、动态信息和未知信息,如图12所示。User和Item的共同作用产生了当前的具体的行为,这里称这个模型叫做多维度模型。
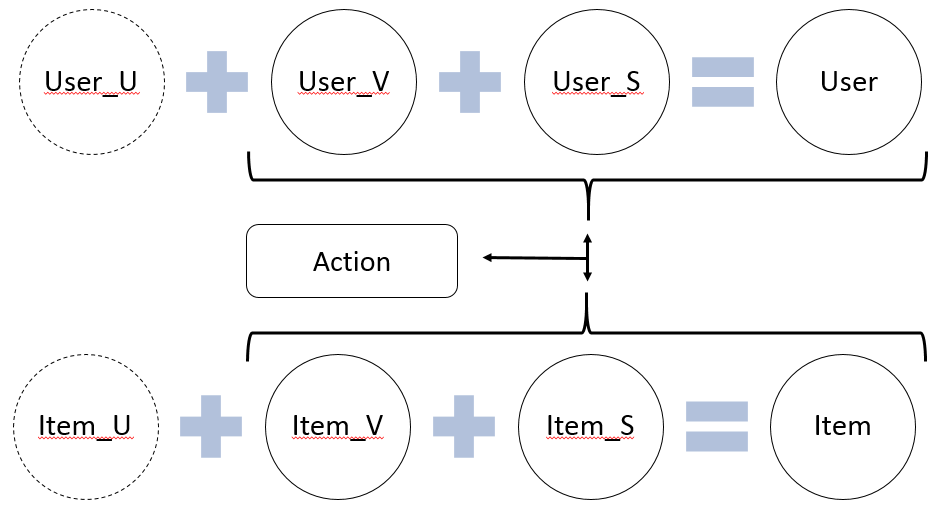
图12中,User_S表示User的静态已知属性(如性别),User_V表示User动态的已知属性(已经发生的行为),User_U表示User无法获取的属性,Item_S表示item静态的已知属性,Item_V表示item动态的已知属性,Item_U表示item无法获取的属性。
根据这个多维度模型,可以对目前一些常用的推荐算法进行统一,如图13所示。
多维度模型下的算法设计
1. 学习User和Item的各维度的特征
这个过程本质上是在数据集上寻找规律,用以描述整体数据的特性。所使用的数据包括User画像数据,Item画像数据以及相互之间的行为数据。User和Item直接的规律可以表示为:
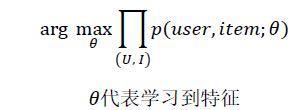
不考虑不可知项,动态属性且只考虑User和Item之间的行为,记为action(user, item)

通过上述,可以学习到action(uv, iv), us, is 的特征表示。
2. 对User进行建模
描述动态个体数据,根据规律获取对User在不同算法下的推荐结果。
单用户时序序列建模,去学习每个人各个时刻的𝑢𝑣, 𝑖𝑣。
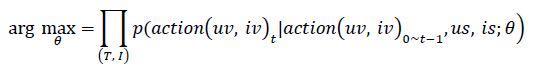
基于之前学习到的𝑢𝑣, 𝑖𝑣表达,使用时间序列针对每个用户进行建模,得到每个用户在任意时刻的表达,用于下一时刻推荐,模型采用浅层RNN网络。
3. 排序和过滤
学习User对不同算法的推荐结果的偏好程度。
排序算法
为每组推荐结果进行标记,记为𝑅_𝑘,表示第𝑘个推荐结果。
统计在不同的推荐场景下,各个时刻的用户行为和推荐结果的一致性,得到用户对算法的偏好(𝐿𝑒𝑎𝑟𝑛 𝑇𝑜 𝑅𝑎𝑛𝑘)。
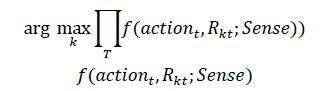
衡量在场景Sense下,t时刻,user行为和第k个算法推荐结果的一致性。这里简要说明,对于推荐的排序要考虑场景的必要性。以某电商推荐为例,流式推荐用户的意图相比于进入详情页或加入购物车的场景中的意图要弱,所以侧重多样性的推荐会更加合理;进入详情页后应侧重相似推荐,而购物车页面则应该侧重搭配推荐。
3.根据计算出来用户对推荐算法的得分,对推荐结果进行加权组合。
4.根据设定的过滤规则对结果进行过滤,包括已下架、性别过滤等过滤规则。
效果展示
FAV_CATE和FAV_CATE_AB(看了又看、看了又买、喜好类目等多种协同策略组合)是目前某电商流式推荐主要采用的策略,也是效果比较好的算法。FAV_CATE_AB是带有负反馈的FAV_CATE,相比FAV_CATE,其点击率和转化率均有所提升。
统计2016年10月06到10月17的平均转化率,本文所提出的基于多维度建模的推荐算法,转化率分别是FAV_CATE_AB的151%~245%。
总结
本文简单介绍了笔者在深度学习方面的一些实践工作以及一些认识。目前,几乎所有的机器学习方法,包括深度学习,本质上都是在统计数据,从中归纳出模型。深度学习只是采用了更加深层次的神经网络,以表达更加复杂的规律,或者对处理的对象进行表示。深度学习对于图像处理领域提供了一种有效的对空间进行结构化方式(CNNs),同理对于推荐系统领域则是对时序序列进行了有效的表示(RNNs)。值得注意的是,无论对空间和时序的表示,其实都是不充分的。目前的深度学习也仅仅对对象的某一方面进行表示,它无法对对象进行完整的描述。再者,空间和时序在进行处理的时候都存在局部性或截断问题,导致即使对这一方面的表示也是存在近似的。所以,机器学习、深度学习要实现真正的智能或理解依旧需要很多的工作。
参考文献:
[1] Sun Y, Wang X, Tang X. Deep learning face representation from predicting 10,000 classes[C]//Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on. IEEE, 2014: 1891-1898.
——祁斌川
网易杭州研究院数据挖掘部
小编点评:深度学习是当前最为热门的机器学习算法,在网易杭州研究院内部已经有广泛的应用,包括对游戏业务的创新,也包括对网易云的智能客服解决方案、内容安全解决方案的支撑。对于深度学习的未来,Facebook的Yann LeCun等大神都推崇无监督学习,但无监督深度学习目前难度还很大。本文作者虽非“科班出身”,却也从业务的角度为我们展示了一种弱监督学习的实现,并介绍了深度学习在推荐领域的探索,这也是业界罕有成熟用例的领域,相信这些分享对希望应用新技术提升业务的团队能带来很多启发。而对于网易云而言,这些前沿的探索成果,都会在恰当的时期集成到各个合适的场景化解决方案之中,为网易云的用户创造更大的业务价值。如果您对深度学习以后不同的看法,欢迎评论讨论。
文章来源:网易云 https://zhuanlan.zhihu.com/p/36906900
相关阅读: