问题背景
近日看到有网友发出疑问,有些平台是如何识别出我那些私藏的小电影的。除了这位网友外,也有人在知乎上提出问题,询问图像识别的技术原理是什么?XX是如何过滤色情内容的?图像识别很难吗,到底难在哪里?也有人“灵魂拷问”,你们人工智能鉴黄的原理到底是什么?
基于这些疑问,网易易盾实验室的工程师写了篇“智能鉴黄”的科普文章,以下是相关内容。
正文
智能鉴黄作为内容安全的核心诉求,一直吸引着学术界和工业界的无数攻坚者来挑战,正如深度学习入门容易精通难,智能鉴黄领域也容易出现从入门到放弃的过程。虽然网上爬一批数据标注一下,训练一个模型就能实现初步的效果,但是商业级别的应用真的这么简单吗?
这篇文章将以易盾的智能鉴黄产品为例,从算法层面介绍智能鉴黄相关的背景和难点。作为算法爱好者的你,一定是因为对算法的浓厚兴趣而不只是为了看某些图像而看这篇文章的。
现状
目前大部分公司的智能鉴黄产品都将输出标签设计为色情、性感和正常三大类,如下所示,显示细分类结果的比较少,一方面原因是细标签定义的难度较大,另一方面是识别效果很难把握,识别效果做得不好,那就是搬起石头砸自己的脚,因此目前大部分产品还是统一输出色情这一大类。
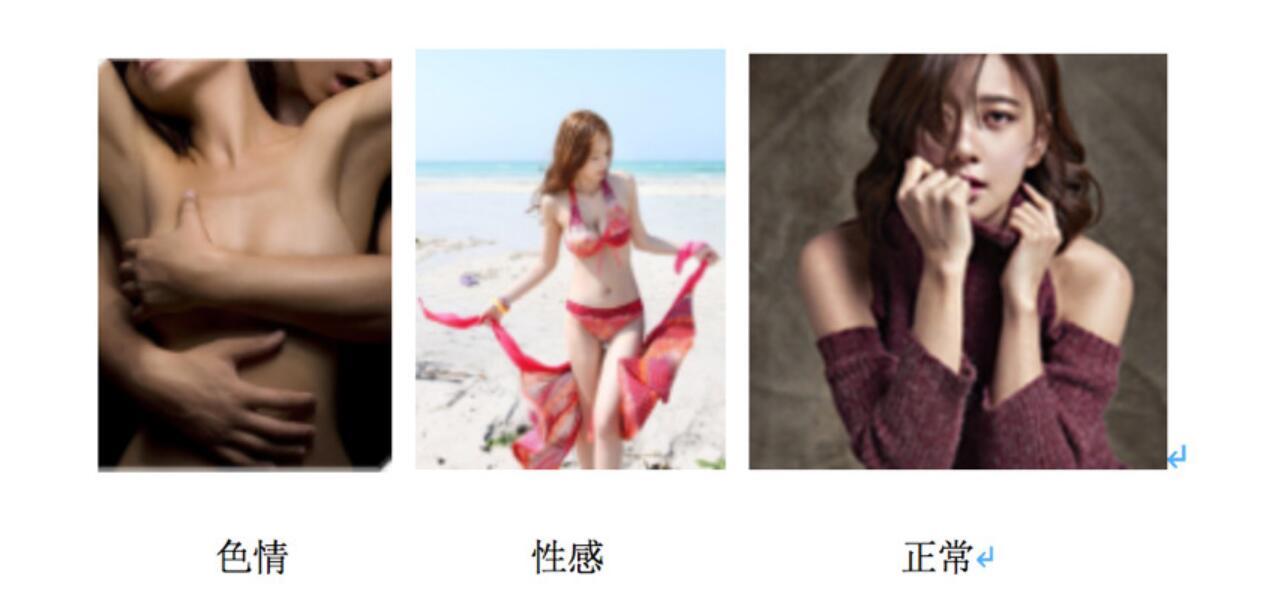
早期的鉴黄大部分是简单粗暴的人工审核,是劳动密集型工种。但是随着图像数量的增加,人工审核成本越来越高,因此采用机器+人工的方式鉴黄就成为了主流。机器+人工的方式一般是先通过机器过滤出大部分一定正常和一定有问题的图像,剩下的再交给人工进行审核,这样可以大幅度降低人力成本,而且机器识别效果越好,人工审核成本越低。
机器鉴黄其实是比较宽泛的概念,可以是通过规则系统来实现,比如基于MD5、基于用户的IP等信息设置黑名单库,直接基于规则进行拦截。当然大部分还是会采用算法模型,也就是用算法模型判断一张图像中是否包含色情信息,本质上就是图像识别。图像识别作为人工智能热潮下的宠儿,这几年的发展可谓日新月异,主要经历了深度学习兴起前手工设计特征到深度学习时代通过网络学习特征的过程,目前在部分任务上的效果甚至超越了人类。
图像识别中最常见的就是图像分类算法,从AlexNet到VGG,从ResNet到DenseNet,目前的图像分类算法可以较为准确地区分ImageNet的1000类数据,鉴黄本身也是对输入图像做分类,因此采用图像分类算法就是顺其自然的事。其次,目标检测算法可以用来检测色情图像中的露点部位,也是比较可靠的手段。此外,还有基于业务层面构造的特征和逻辑,比如是否有人、皮肤的面积等,用来辅助判断,在一些情况下确实是有效的。
除了图像层面的鉴黄外,视频层面的鉴黄可以有更多样的解决方案,最基础的是通过视频截帧依靠成熟的图像鉴黄算法实现,其次还可以直接基于视频做分类、行为分析等,借助时序特征实现更加可靠的识别。除此之外,音频层面的特征也是非常有用的,正常视频中应该很少会听到娇喘的声音。
主要难点
其实不管是基于图像层面还是视频层面做智能鉴黄,只要有一定的数据积累和恰当的解决方案,基本上对于明显的露点色情或者明显性行为图像都可以有不错的召回能力,那难点到底在哪?我这里大致列举了几个。
- 不露点色情
对于智能鉴黄而言,色情这个概念太大了,比如敏感部位、性行为、色情挑逗等,大致上可以分为露点的和不露点的,露点的大家都比较熟悉,识别起来也相对容易。不露点的除了部分性行为比较容易外,其他的比如姿势极其挑逗,衣着极度暴露(丁字裤、情趣内衣等)等类型其实在特征上和性感是很接近的,识别起来有一定难度——请看图。

- 卡通、漫画、简笔画色情
这种类型的图和真人还是有一定差异的(如下图),试想你看到一张漫画裸女和一张真人高清裸女的反应肯定是不一样的,模型也是人训的,所以道理是一样的。卡通、漫画和简笔画主要的两个特点就是夸张和简单,夸张的话特征就和真人存在一定差异,比如把敏感器官画得超级大;简单的话特征就很少,尤其当图像中只是黑色线条时,可提取的有效特征很难支撑模型做出准确的识别,在这种情况下,那些计算皮肤面积的算法显然无能为力了。

- 色情特征小
特征较小(可以自行脑补一张远远拍摄的裸女~)其实是目前图像识别中较为普遍的难题,本质上是大面积的背景噪声和小面积有效特征之间的矛盾。常规的图像分类算法和目标检测算法都是针对全局图像进行特征提取的,在这种情况下这些小区域的色情特征很可能就被大面积的正常特征所掩盖,这就大大增加了识别难度。
这方面也不是没有解决方案,比如可以:
- 借助attention思想让分类网络在训练过程中将注意力放在对分类输出最有利的区域,直接从单模型层面提升效果,实现上既可以从网络结构设计上来做,比如像SENet自动学习特征权重;
- 从监督信息角度来做,毕竟常规的图像分类算法一般只有一个全局的分类监督信息,网络结构上的attention也是基于全局的分类监督信息进行训练的,有点粗暴学习的感觉,但其实这不一定是最优的,假如针对局部区域还有额外的监督信息,或许会让网络的训练更有针对性;
- 借助目标检测、人体关键点检测等算法来辅助鉴黄,比如检测出人体或肢体(动植物色情暂不考虑~),裁剪出最有可能包含色情信息的区域进行识别。
- 非通用色情
非通用色情中最直观的例子是情趣用品,比如震动棒、跳蛋等,相信大家都不陌生。直观上情趣用品的危害程度上可能不及通用的色情,但假如一个面向青少年的APP每天都在传播各种情趣用品图像,显然不能袖手旁观。
这种类型的难点在于难以平衡好误漏判,看看下面这2张震动棒和跳蛋的例图就知道了。一方面和情趣用品外形相似的物体太多了,比如一些儿童玩具;另一方面线上数据中情趣用品的占比太少了(可能百万级别的数据才会出现几张),所以大部分情况下,可能为了召回情趣用品图像就会带来较多的误判。

图像攻击
只要某个行业有利可图,就会不断有人涌入,色情相关的行业也是如此。色情图像、电影等需求的增长和国家对色情的明令禁止之间的矛盾,诞生了越来越多的黑产组织,这些组织人员千方百计地要将色情广告信息借助各种媒介传输出去,而易盾作为内容安全服务提供商,则是要想方设法拦截这样的信息,这就是一场图像攻防的持久战。我们可以大致将黑产组织的图像攻击分为非算法攻击和算法攻击两种。
- 非算法攻击
大部分的黑产组织人员都是采用PS软件对色情广告图像做一定的处理后,企图绕过鉴黄服务,常见的处理操作包括对色情特征做一定程度的掩盖(马赛克)、将色情图像缩小后贴到另一张正常图上(特征小)、图像模糊处理等,这些其实对模型来说是比较难的,需要有一定的数据积累和算法层面的优化,才可以在一定程度上拦截掉这些数据。
- 算法攻击
俗话说不怕流氓耍无赖,就怕流氓有文化,采用算法攻击的黑产组织,简直就是有文化的流氓。试想一个黑产组织招了一个算法工程师,通过图像对抗攻击算法,往色情图像加入少量噪声就能左右鉴黄模型的识别结果,轻轻松松攻破你的防线,顿时有种后背发凉的感觉。
图像对抗攻击是比较活跃的一个研究领域,目前许多算法都是基于梯度来实现的,包括最经典的FGSM算法。FGSM算法的核心就是下面这张熊猫图,在一张正常的熊猫图像上加一点攻击噪声得到一张肉眼看起来还是熊猫的图像,但是模型却将其识别为长臂猿。

总结
整体来看,经过多年的数据积累和算法沉淀,目前智能鉴黄的识别效果可以做到非常准确了,今后需要做的更多的是针对边界数据的识别优化,比如色情挑逗、极度暴露、情趣用品等。
同时,智能鉴黄也将慢慢往精细化分类发展,除了区分不同的部位、行为外,还可能区分成人和幼儿,真人和卡通等。易盾算法团队在上述这些方面也已经做了充分的技术挖掘,取得了很不错的实际效果,并且算法识别能力还在稳步上升。
最后,智能鉴黄路还很长,需要不断进化。