作者:张俊,网易杭州研究院测试工程师
1. 背景
Hive是Apache开源的数据仓库工具,主要是将基于Hadoop的结构化数据文件映射为数据库表,并提供类SQL查询功能。Hive最初的目标是为了降低大数据开发的门槛,它屏蔽了底层计算模型的复杂开发逻辑,类SQL的查询功能也便于数据应用的开发,但Hive并不适合哪些低延迟的查询服务,如联机事务处理(OLTP)类查询,主要用于离线数据分析,数据量一般都巨大,一般会有分钟级的查询延迟。
随着大数据的发展,Hive衍生出了基于Thrift的RPC服务Hiveserver2、Metastore,便于进行规模化的运维及扩展。网易杭研研发的大数据平台网易猛犸的数仓建设及离线分析均是基于Hive,权限、血缘及其他基于Hadoop的类SQL计算引擎也与Hive密不可分。面对业务数据分析需求的不断增加,数仓及数据开发任务的规模也在不断扩大,给Hive带来的挑战也越来越大,一旦服务的稳定性出现问题,用户侧所有的数据应用也都可能陷入瘫痪。
从线上Hive的历史运维及发展来看,主要存在以下几个痛点:
○ 社区版本遗留的问题:线上故障频繁出现,大压力场景下服务FullGC、异常退出等情况;
○ 依赖组件带来的风风险:服务链路较长,依赖服务的异常往往会导致Hive服务出现不可恢复的异常;
○ 变更带来的风险:随着业务的发展,血缘、权限、UDF的扩展越来越多,往往会对服务带来不可预知的影响。
痛定思痛之下,我们将Hive的稳定性保障作为工作的重点,目标是提升Hive服务的可用率,一方面保证版本迭代更新后线上服务稳定可用,另一方面当故障出现时有对应的预案,能够快速的恢复,减少故障的定位及恢复时间。
2 Hive稳定性测试分析
2.1 线上问题分析
在进行Hive的稳定性测试之前,首先需要对线上当前的稳定性问题进行分析,综合历史所有的线上故障,主要原因在以下几个方面:
○ 大并发大压力场景下,服务偶现异常;
○ 大数据场景下的特定SQL导致服务内存溢出。
○ 扩展JAR可能会导致服务进程异常退出;
○ 依赖组件的异常导致服务不可用且无法恢复。
基于上述的问题,主要从压力测试、故障注入两个方面来进行保障。在压力测试方面,除了需要流量模型的构造外,还需要重点关注请求SQL、数据场景,这就需要对线上场景充分分析后进行模拟,在故障注入方面,需要首先对架构及链路进行分析。
2.2 压测方案
2.2.1 测试环境
Hiveserver2/Metastore 线上部署均采用Zookeeper来做高可用及随机的负载均衡,且均为混部的方式(即Hiveserver2、Metastore 部署于同一节点),以线上某集群为例,存在2节点的Hiveserver2及Metastore。
稳定性测试环境的部署拓扑需要与线上保持一致,且服务的核心配置需要与线上保持一致或者按照服务器规格进行一定比例的缩小。这里需要重点关注的是,线上线下最大的差异在于底层的存储及计算资源,线上Hadoop集群规模往往在数百个节点甚至上千个节点,线下测试环境受限于成本,一定与生产环境存在较大差异,这就需要在铺地数据、流量构造方面针对测试环境资源进行针对性的构造。
2.2.2 SQL场景构建
综合对于HQL的分析,可以将SQL大致分为三类,DDL、DML及DQL
○ DDL主要是Hive库、表、列、分区进行创建、修改、删除相关的操作,此类操作一般SQL相对简单执行耗时较短,主要的压力在于对于Metastore元数据的增删改查。这里需要重点注意partition的数据铺地,在Hive元数据中通常来说只有partitions数据可以达到百万级别(库表数据的量级往往较小)。
○ DML为数据操作语言,涵盖Hive表数据增改操作,Hive对于Update的支持一般,此类语法一般没人用,所以重点关注Hive表的导入操作,及主要包含Load及Insert语法。由于可能涉及数据的迁移及聚合等操作,此类SQL往往伴随着MR的执行,由于测试环境计算资源、存储资源有限,模拟时需要适当减少MR操作的比例。
○ DQL语句,主要包含查询、计算类的SQL,与DML一样此类SQL往往也会伴随着MR任务的产生,故此类SQL的比例也会适当降低
理想状态下,线下稳定性测试的请求场景应该更加贴近线上,通常会采用线上引流的方式来进行构造,但是但是对于大数据场景来说,请求SQL与业务数据、元数据一同构成了用户场景,脱离数据及元数据的用户请求SQL毫无意义,而由于数据量级的巨大,线下无法对这部分数据进行模拟,因此我们采用了“曲线救国”的方式来进行构建。
稳定性测试的目标主要在于hiveserver2/metastore服务的稳定性,复杂MR任务的SQL的瓶颈在于底层计算资源,且SQL的场景很难枚举,盲目追求与线上SQL场景完全一致反而会导致由于底层计算资源的不足,导致实际压测对象的偏差。实际在稳定性测试的流量构建中,主要以之前积累的DDL、DML、DQL 语法SQL为基础,为了解决SQL复杂度上的问题,我们引入了业内衡量大数据性能指标的基准测试集合TPC-DS作为请求SQL场景中的一部分。除此之外,一部分特定的用户SQL场景也会带来稳定性方面的问题,此类问题往往伴随着特定的数据场景或者特定的UDF场景,如对于分区数百万级的表,进行查询或者JOIN操作会来服务内存的极大增加,因此这类SQL也会纳入稳定性测试的SQL场景中。
综合上述分析过程,大体明确SQL场景主要以基础的SQL集合、TPCDS SQL集合及积累的线上问题SQL场景来组成,由于业内并没有统一的衡量SQL复杂度的标准,Hiveserver2 metrics 中的sql_compile的耗时可以在一定程度上反应SQL的复杂程度,实际在构造压力模型时,会根据线上监控数据结合Yarn计算资源,调整各类SQL的比例。
2.2.3 铺地数据构造
Hive铺地数据包含两部分,一部分为HDFS上存储的业务数据,另一部分为存储在MySQL中的元数据信息。
对于HDFS上存储的业务数据来说,最理想的状况一定是在数据复杂度及数据量级上保持跟线上一致,HDFS的真实数据量级往往在TB甚至PB级别,受限于数据安全性、集群规模的影响,测试环境无法直接使用线上数据也无法保证跟线上数据规模一致。
在真实数据的复杂度上,TPC-DS的基准数据已经能在一定程度上模拟了OLAP的数据分析场景。数据规模方面,考虑到数据的扩张带来的主要底层Hadoop集群的计算及存储压力,对于Hiveserver2 带来的压力有限,因此这里不再纠结于数据量级的多少,而且直接采用百GB级别的TPC-DS基准数据作为铺地。
在MySQL存储的元数据信息方面,为了贴近线上真实场景,这里就简单粗暴的直接复制线上RDS中数据作为铺底。
2.2.4 流量构造
稳定性测试的压力模型往往分为以下几个阶段:
○ 恒定压力阶段:在恒定大压力场景下,系统可能出现吞吐量TPS的抖动、响应时间的波动等;
○ 基于线上请求场景构建的压力模型:通过对服务在线上运行情况的监控,不难获取到不同时间点,线上业务的流量波动,此类流量往往伴随着峰值峰谷压力,且一般来说每天的压力波动情况比较固定,例如对于Hive来说,离线分析任务的请求往往在凌晨后达到峰值,此类请求量突增的情况,往往会暴露出服务中隐藏的稳定性问题,如出现内存异常、服务宕机等情况。
○ 在恒定压力的基础上引入异常的干扰,如注入CPU波动、网络延迟或者依赖组件出现服务异常等。引入异常注入往往会在恒定的压力场景下实现,否则无法分析指标的变化是否是因为流量的波动带来的影响。
在通常的业务场景中,压测中的压力模型数据往往来源于性能测试中的瓶颈数据,业内往往会用拐点性能数据的80%作为压测时的并发数据。在Hive服务中由于对响应时间的要求并没有那么苛刻,离线计算任务的耗时经常在分钟甚至小时级别,且整个计算链路上的瓶颈一定不在Hiveserver2、Metastore上,而是与集群的计算资源、存储资源相关,所以我们在稳定性测试前,并未做系统的性能测试来确定服务的拐点性能数据,因此在压力大小方面,我们即以线上核心集群的峰值请求流量来进行构造。
那么如何来评判引入的压力已经至少达到了线上压力的负载呢?得益于Hive服务较为完善的服务监控指标,我们主要从以下两方面来进行判断:
○ 服务器的基础资源占用,Hive服务对磁盘、网络的要求并不高,因此重点关注稳定性测试中的CPU、内存是否能达到跟线上的服务监控数据匹配;
○ Hive服务Metrics监控数据,主要通过open_connections来判断流量是否达到预期,以及压力模型是否与线上场景一致;
2.3 异常注入
分析Hive服务需要注入的异常前,首先来对服务的架构及链路进行分析。

Hive服务包含Hiveserver2/Metastore,这里忽略HiveClient的执行方式,主要关注服务的运行稳定性。
○ Hiveserver2/Metastore 通过Zookeeper实现高可用,用户执行SQL时通过Zookeeper随机选择其中一个节点请求。
○ SQL提交后主要通过Hiveserver2实现编译、执行等过程,这个过程中需要与RM、NN节点交互,同时需要与Metastore交换元数据信息。
○ Metastore服务主要提供元数据相关的API,并通过hooks插件实现元数据同步、权限控制、血缘生成、lifecycle表等功能。
○ Metastore元数据存储在MySQL上(线上采用RDS),实际数据存储在HDFS上
结合上述的架构分析梳理出请求链路上的强弱依赖,我们将Hive 依赖的服务分为两类,一类为强依赖,即完整执行链路上必须要交互的组件;一类为弱依赖,即异步调用或者调用失败不会影响执行状态的组件。
强依赖组件包含:MySQL、HDFS(NameNode)、YARN(ResourceManager)、Zookeeper
弱依赖组件包含:RangerAdmin、Kafka、MongoDB
对于强依赖组件来说,需要关注调用失败后任务的异常反馈及服务异常日志是否清晰,以及大批量失败的情况下对服务运行状态的影响及恢复后任务执行是否恢复。
弱依赖组件的异常一般不会影响任务的执行状态,但是需要关注大批量、长时间执行的情况下,异常是否会影响服务的性能、资源占用,比如是否会导致线程池满,是否会出现内存溢出等情况。
3 Hive稳定性测试实践
3.1 测试环境
参考线上环境拓扑与配置,测试环境也采用Hiveserver2/Metastore节点混合部署的方式,hiveserver2/metastore服务部署的机器配置与线上差异不大(CPU cores存在区别),主要区别在于底层计算节点,线上对接的为970+的计算节点,而线下仅有5节点,能够使用的计算资源相差较大,实际测试时需要减少MR类型SQL运行比例。
由于Hiveserver2/Metastore 部署机器与线上基本一致,所以服务的相关配置也按照线上进行了修改,关键配置项均与线上保持一致。
3.2 压力测试
测试SQL场景
由上述的测试分析可以得到,稳定性测试中SQL场景主要采用以下几类:
○ 基础SQL语句:包含常规DDL、DML、DQL语句
○ 部分TPC-DS SQL场景
○ 来源于线上特定用户场景的SQL,如用户UDF、复杂分区条件下的表查询操作。
所有的SQL执行均遵循新建表——>执行测试SQL操作——>删除表操作,以保证压测过程中不会互相干扰。SQL场景构造过程中并没有完全按照线上真实SQL模拟,故线下压测使用的SQL复杂度可能会小于线上(由于复杂类别的SQL均伴随着MR任务的执行,并且计算节点的资源不足,不可能完全与线上保持一致),为了平衡此类问题,SQL场景中实际加入了部分TPC-DS SQL,通过调整此类复杂SQL的比例来达到控制整体SQL复杂度的目标。
通过hiveserver2的metrics的compile_api的指标可以看到当前花费在编译上的平均耗时,此指标实际与SQL的复杂度挂钩,可以大致看出SQL复杂度情况,通过下图监控数据对比可以看到在编译平均耗时上,线上与线下基本能够达到一致。

铺底数据
由之前的分析过程可以看到,这里的铺底数据包含:
○ 关系型数据库(RDS)的元数据
○ HDFS上存储的真实数据
元数据的数据库量主要影响Metastore API的性能,这里采用了比较简单粗暴的方式,直接将线上集群的元数据导入稳定性测试环境作为铺底。除了铺地的元数据外,需要根据压测场景中的SQL构造对应的元数据,这里包含若干raw_table及tpcds-ds表。
由于HDFS集群与线上体量依然差距巨大,这里忽略了NN由于数据量级差异导致的性能差异,没有针对性构造HDFS铺地数据,实际测试中使用的数据均来自于TPC-DS。
流量构造
压测工具
由于并没有良好兼容大数据认证体系的性能测试工具,这里依然采用Jmeter来施压,通过开发jmeter插件的方式,封装kerbores认证及JDBC请求,并通过Jmeter BashShell Sampler来执行。
通过维护多个线程组并设置不同并发线程数来设置不同类型SQL的执行比例。
在非恒定流量的构造上,采用了Jmeter提供的Ultimate Thread Group插件来实现,通过线上压力模型的分析,来构造稳定性测试中使用的流量曲线。
压测流量
通过前文分析,Hive稳定性测试中的流量均需要来源于线上,实际在操作过程中,在恒定流量场景中,我们采用的为线上峰值流量,而在非恒定流量场景中,我们对线上24小时的流量数据分析后,进行建模,并通过上文介绍的jmeter插件Ultimate Thread Group来进行模拟。
实际测试过程中,也分别通过监控数据与线上进行比对,主要从服务器资源使用率、服务metrics数据指标等方面来判断是否达到或者接近稳定性测试的压力负载。以恒定流量场景中的连接数指标来举例,如下图所示。这里可以看到稳定性测试中连接数指标与线上峰值流量基本一致,结合服务器内存资源占用情况大致可以看出流量的注入符合预期。
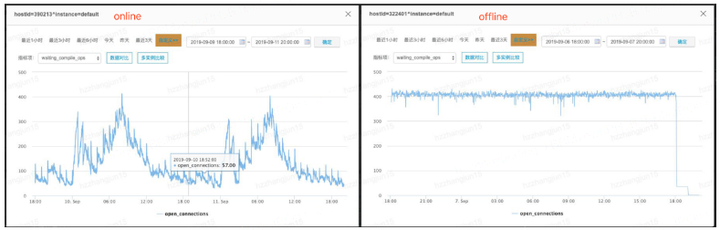
当然从恒定流量、非恒定流量场景下我们均看到部分监控数据与线上存在不一致的情况,如CPU 使用率线下往往能达到70~80%左右,但线上只有15~25%左右,主要问题也在于线下测试由于考虑到集群资源的问题,减少了复杂SQL(伴随着大量计算资源的消耗)的比例,此类SQL在提交MR执行后即处于等待任务结束/调度提交MR任务的阶段,因此会有着较低的CPU消耗。
需要说明的一点是,Metastore的服务压力往往比Hiveserver2要大,测试环境在模拟时,所有的流量入口均是Hiveserver2,因此为了保证Metastore的压力负载,这里的流量数据采用的均为Metastore服务的线上峰值数据。
3.3 异常注入
前文的分析过程中,我们已经根据Hive的框架及链路大致梳理了服务的强弱依赖,在稳定性测试的后续阶段,我们也将这部分异常干扰加入到稳定测试执行中。
故障注入的手段这里不再赘述,我们采用的为网易杭研QA组开发的磐石故障演练平台,一键化的故障注入及性能指标收集也便于后续的分析及复用。
在注入故障的类别上,依赖组件主要从服务完全不可用、服务请求延时两个方面来进行模拟,服务不可用可以从依赖组件的进程异常来进行模拟,如进程强杀、进程假死。服务请求延迟的原因可能有两点,一是依赖组件的性能异常或者存在性能瓶颈(可以通过JVM注入异常来模拟),二是出现网络延迟的情况,以上异常场景均可以通过磐石平台来进行注入。
以依赖组件NameNode为例,注入响应延迟异常(通过网络延迟来模拟),设置延迟时间为3s(连接超时时间默认为150s),当注入异常后,HiveSQL响应时间未出现明显下降,但是随着而来的是Metastore连接数的突增,当异常恢复后,连接数依然无法释放,一旦达到Metastore设置的max connection数,则会引发用户请求直接被抛弃,用户任务失败。
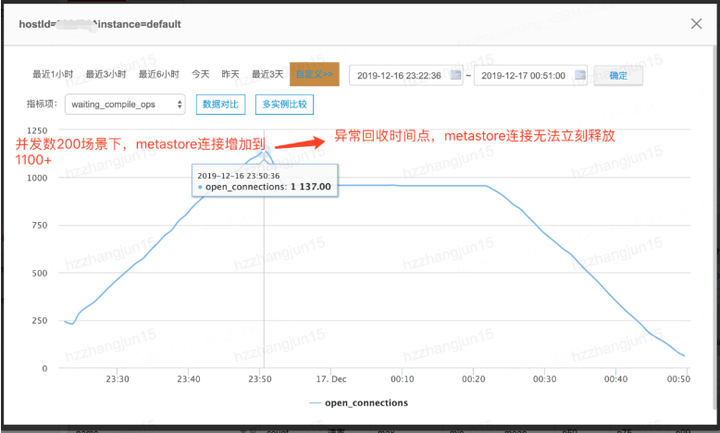
通过对此事的堆栈进行进行分析后发现,连接关闭时均需要调用NN api去删除存在于HDFS上的临时数据,当网络出现延迟或者NN性能瓶颈时,则会出现堵塞,导致连接无法释放。由于Hive社区架构问题,此类问题往往不会直接修复,而且采用预案的方式进行处理,即当NN性能恢复后,如在30s内连接数依然无法下降至预期值,则重启Metastore服务,从而控制由于此类稳定性问题带来的SLA 损失。
3.4 稳定性测试结果的评估
上文中已经谈到了Hive稳定性测试的分析及大致的实践过程,那么如何去评估稳定性测试是否通过呢?
对于Hive服务来说主要从以下几个方面来判断:
○ TPC、响应时间的波动情况,在恒定压力测试阶段,理论上来说压测的TPC及响应时间的波动范围应该较小,如出现波动较大的情况,即需要结合其他服务指标进行分析确认;
○ 服务资源占用:这里主要通过内存资源来进行判断,需要检查是否存在内存泄露的情况,另外通过哨兵的GC监控也能够看到GC及内存使用率方面数据是否存在异常,如出现频繁FullGC或者FullGC后资源无法释放,则也需要判断是否存在内存泄露问题。
○ 服务Metrics指标,得益与Hive延续多年的社区开发活跃度,Hive的Metrics数据也较为健全,可以通过服务指标的波动来验证是否存在稳定性问题,如hiveserver2/metastore服务的open_connection数,结合当前的并发数,可以判断是否存在连接泄露等问题。
除此之外,大数据运维监控平台(smilodone)也提供了准实时的HiveSQL分析系统,可以通过对异常SQL执行的日志进行分析,继而判断是否与服务的稳定性相关。
我们目前已经将稳定性测试纳入Hive版本迭代的准出标准之中,但并非在每个版本中均经历上文谈到的稳定测试的几个阶段(恒定流量阶段、非恒定流量阶段、及异常干扰注入阶段)。在日常维护版本考虑到更新影响及迭代时间,往往只会进行3*24小时的恒定流量压力测试,当出现核心编译器更新或社区大版本更新时,则会在时间充裕的前提下,将上述三个阶段尽数完成,已更加充分的评判服务的稳定性是否达标。
4. 稳定性测试总结及展望
结合Hive的稳定性测试实践,发现的问题重点集中在以下几个方面:
○ 系统问题:系统配置引发的服务稳定性问题,如操作系统的最大进程数、最大句柄数等
○ 依赖服务问题:依赖服务的性能问题引发Hive服务性能降低,如NN性能瓶颈带来的Hive响应时间增加、连接无法释放;
○ 服务扩展带来的不可控问题:如血缘插件带来的内存泄露问题、UDF引发的服务宕机问题。
○ 特定SQL场景引发的内存泄露问题:如百万级分区场景下的查询操作引发服务内存泄露问题。
对于稳定性测试中发现的问题并不一定能够通过代码手段来进行修复,例如对于开源版本遗留的架构问题,因为此类问题涉及的改动往往较大,牵一发而动全身,修复问题带来的不可预知性后续维护的成本可能更高。
那么如何来应对线上可能存在的此类已知风险呢?我们通过联合SRE、开发一起推动预案、监控手段的完善,在hive组件层面做到所有的线上已知风险均有应对预案,并且联合开发(线上故障的处理人)在线下进行定期的预案演练,不断完善监控方案及开发应对故障处理的效率。
从长远来看,线下的演练验证只是第一步,线上演练才是最终目标,后续我们会逐步推进线上演练,逐步完善补充可能存在的故障预案,并通过线上演练的方式来进一步推广预案的有效性。
从线下稳定性测试的角度出发,后续的改进主要从以下三个方向,一是测试有效性的提升,持续的扩充用户场景、故障样本,以期能够更加贴近线上真实场景;二是测试效率的提高,优化压测脚本及故障注入工具,以减少人工干预的成本;三是从测试分析维度,如何更加智能化的评估系统的稳定性、如何更精准度的分析定位问题,将是后续很长一段时间的研究目标。
来源:网易云 原文链接:https://zhuanlan.zhihu.com/p/103101244